Word pair embedding technology, which can improve the performance of existing models on cross-sentence reasoning
Word embeddings are now a standard component of any deep learning-based natural language processing system. However, recent work by Glockner et al. (arXiv:1805.02266) shows that current models that rely heavily on unsupervised word embeddings have difficulty learning the implicit relationships between word pairs. The implicit relationship between word pairs is crucial for cross-sentence reasoning such as question answering (QA) and natural language inference (NLI).
For example, in an NLI task, given a hypothesis "golf is prohibitively expensive", to infer the conjecture "golf is a cheap pastime" requires knowledge of "expensive" (expensive) and "cheap" (cheap) are antonyms. Existing word embedding-based models struggle to learn this relationship.
In view of this, Mandar Joshi, Eunsol Choi, Daniel S. Weld of the University of Washington, and Omer Levy and Luke Zettlemoyer of Facebook AI Research recently proposed the word pair embedding (pair2vec) technique, which can improve the cross-sentence reasoning of existing models. Performance.
Word Pair Embedding Representation
intuition
The intuition of word pair embeddings is simple, and just as context implies the meaning of words (word embeddings), context also provides powerful clues about the relationship between word pairs.
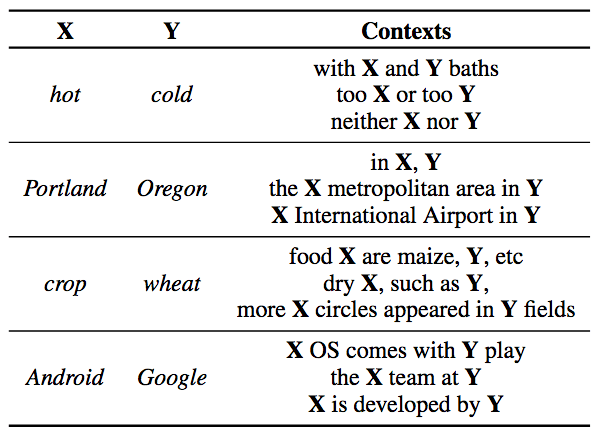
Word pairs (italicized) and their context (taken from Wikipedia)
However, in general, word pairs appear together infrequently in the same context. To alleviate this sparsity problem, pair2vec learns two composite representation functions R(x, y) and C(c), encoding word pairs and contexts, respectively.
Express
R(x,y) is a simple 4-layer perceptron, the input is two word vectors, and the element-wise product of these two word vectors:
where x and y are the normalized embeddings based on the shared query matrix Ea:
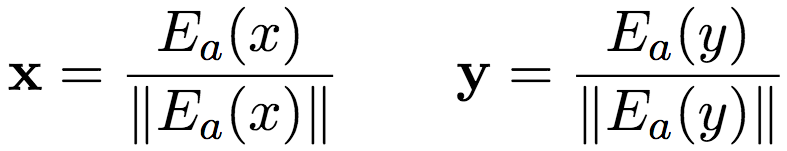
C(n) embeds each token ci based on the query matrix Ec, then passes the embedding sequence into a single-layer bidirectional LSTM, and aggregates it using attention pooling:
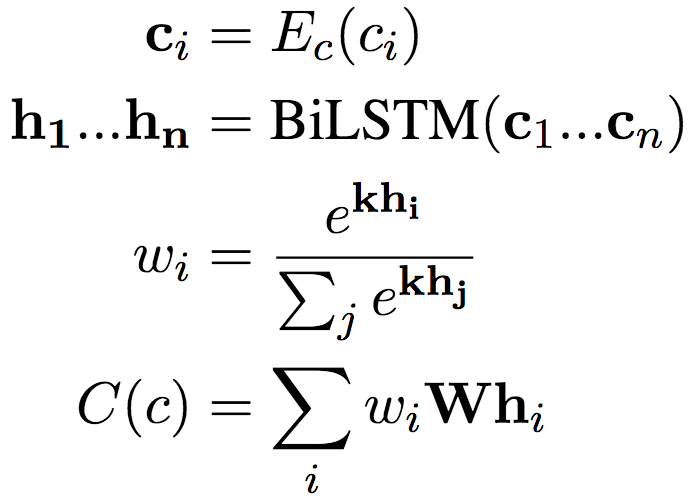
All the above parameters, including Ea and Ec, are trainable.
Target
On the one hand, the optimization objective needs to make R(x, y) and C(c) corresponding to (x, y, c) observed in the data similar (large inner product); on the other hand, it needs to be Make word pairs dissimilar from other contexts. Of course, computing the similarity of all other contexts and word pairs is too computationally expensive, so the authors of the paper employ a negative sampling technique and instead compare some randomly sampled contexts.
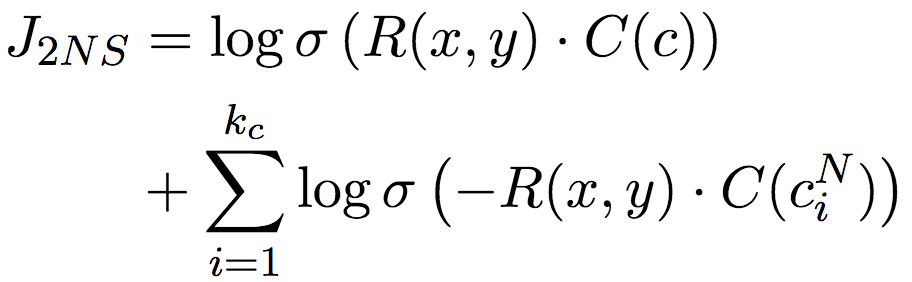
CN in the above formula is the context of random sampling.
This approach is actually in the same line as word embedding. Word embeddings also face the problem that computing all contexts (softmax) is too complicated. Therefore, word embedding techniques such as word2vec and skip-gram use hierarchical softmax (using a binary tree structure to save all words, which greatly reduces the amount of computation). Later, Mikolov et al. proposed that negative sampling can be used as an alternative to hierarchical softmax. Negative sampling is simpler than hierarchical softmax.
Still, remember the word pair sparsity problem we mentioned earlier? This scheme, which directly borrows negative sampling from word embedding, is also affected by this. Therefore, the author of the paper improved the negative sampling technique, not only negatively sampled the context c, but also negatively sampled the words x and y in the word pair, respectively. This ternary negative sampling target completely captures the interaction between x, y, and c:
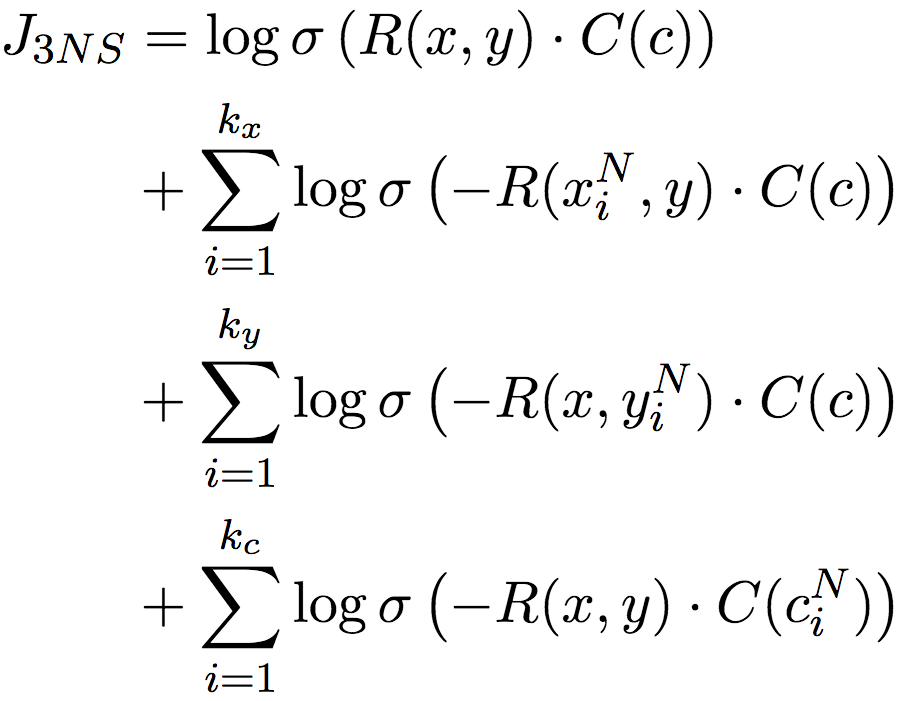
The authors of the paper prove (see Appendix A.2 of the paper) that the goal converges to:
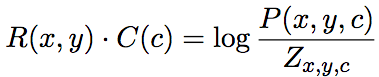
In the above formula, P represents the Elemental Mutual Information (PMI), and the denominators Zx, y, and c are the linear mixture of marginal probability products:
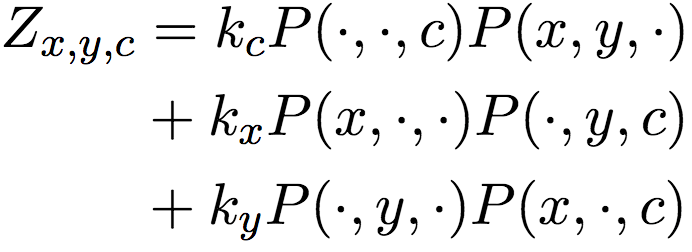
In addition, when negative sampling, in addition to sampling from the uniform distribution, an additional uniform sampling is performed from the most similar (according to cosine similarity) 100 words. This typed sampling approach encourages the model to learn relationships between specific instances. For example, using California (California) as a negative sample for Oregon (Oregon) helps to learn pattern-appropriate word pairs (Portland, Oregon) such as "X is located in Y" (Portland is Oregon). city), but not word pairs (Portland, California).
pair2vec joins inference model
When adding pair2vec to the existing cross-sentence inference model, the author of the paper did not directly replace the word embedding passed into the encoder with pair2vec, but instead inserted the pre-trained word pair representation into the attention of the model by reusing the cross-sentence attention weight. Floor.
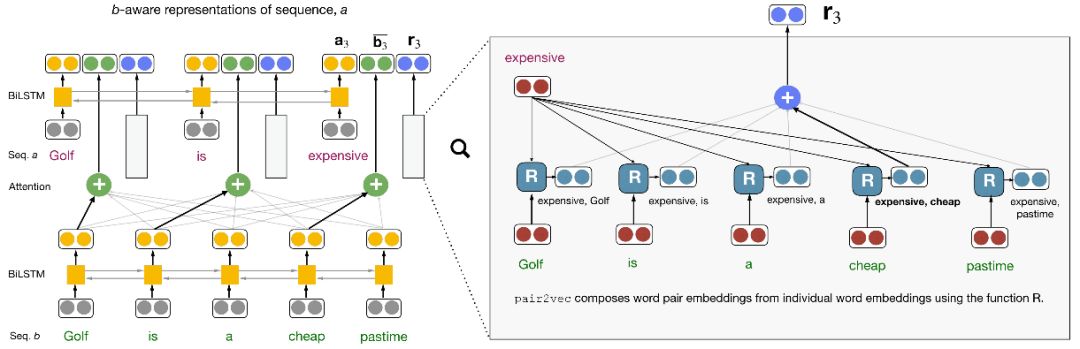
The figure above shows a typical architecture of a cross-sentence attention model (left half) and how pair2vec joins this architecture (right half). To briefly explain, given two sequences a and b, for the word ai in sequence a, the model encodes ai based on a bidirectional LSTM, and creates an attention-weighted representation relative to ai based on the bidirectional LSTM state of sequence b (bold in the figure). The arrows indicate semantic alignment). On this basis, add the attention weighted word pair representation ri(ai, b).
test
data
The authors of the paper used Wikipedia data from January 2018, which contains 96 million sentences. Limit vocabulary size to 100,000 based on word frequency (removed in preprocessing stage). On the preprocessed corpus, the authors consider all word pairs within a window size of 5, and downsample instances based on word pair probabilities (with a threshold of 5 × 10-7). Downsampling can compress the dataset size to speed up training, and word embeddings such as word2vec also use downsampling. The context starts with one word to the left of the pair and ends with one word to the right of the pair. Additionally, the authors of the paper replaced word pairs in context with X and Y.
Hyperparameters
Both word pairs and contexts use 300-dimensional word embeddings initialized based on FastText. The hidden layer size of the single-layer bidirectional LSTM used for the context representation is 100. Each word pair-context tuple uses 2 contextual negative samples and 3 augmented negative samples.
The pre-training uses stochastic gradient descent with an initial learning rate of 0.01. If the loss does not drop after 300,000 steps, then reduce the learning rate to 10% of the original learning rate. The batch size is 600. Pre-trained for 12 epochs (on Titan X GPU, pre-training takes a week).
The task models are all implemented using AllenNLP, and the hyperparameters take default values. No settings were changed before or after inserting pair2vec. The pretrained word pair embeddings use a dropout of 0.15.
question and answer task
Experiments on SQuAD 2.0 show that pair2vec improves by 2.72 F1. Experiments on the adversarial SQuAD dataset show that pair2vec also strengthens the generality of the model (F1 increases by 7.14 and 6.11, respectively).
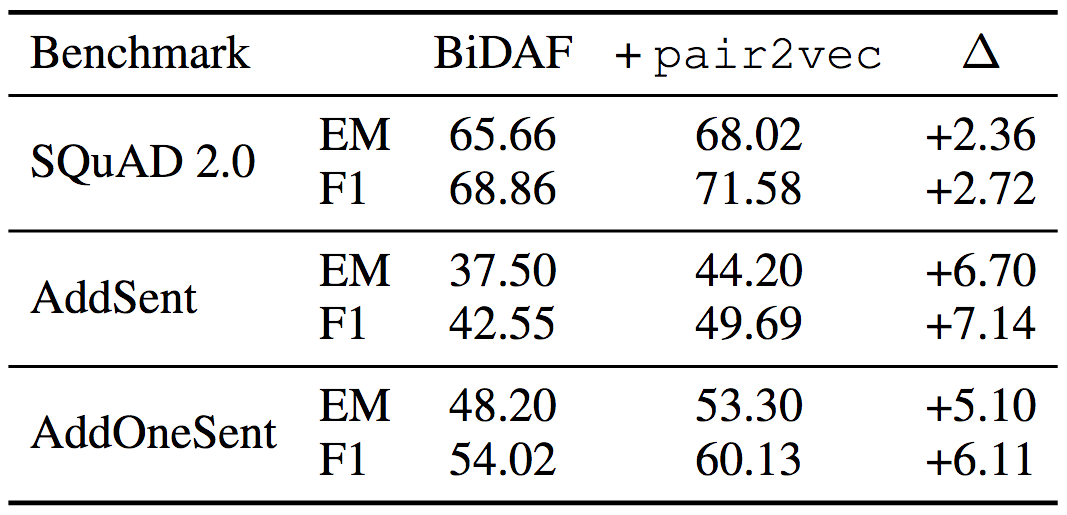
Both use ELMo word embeddings
natural language inference
On the MultiNLI dataset, after adding pair2vec, the performance of ESIM + ELMo is improved by 1.3.

Glockner et al. proposed an out-of-domain NLI test set (arXiv:1805.02266), indicating that in addition to KIM using WordNet features, the performance of multiple NLI models on a new test set that is simpler than SNLI is much worse, indicating that these models generality is questionable. The ESIM + ELMo model after adding pair2vec has reached the current state of the art, setting a new record.
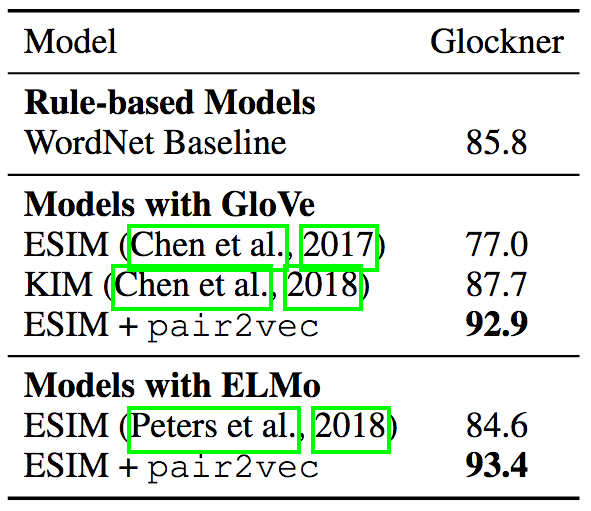
By the way, KIM's approach is the closest to pair2vec in existing research. KIM also adds word pair vectors to the ESIM model, but its word pair vectors are hand-coded based on WordNet. While pair2vec uses unsupervised learning, it can reflect relationships that do not exist in WordNet (such as person-occupation), as well as word pairs that are not directly related in WordNet (such as bronze and status).
word analogy
To reveal what additional information pair2vec adds, and which types of connections pair2vec is better able to capture, the authors conducted experiments on the word analogy dataset.
The word analogy task is to predict a word y that satisfies a : b :: x : y given a word pair (a, b) and a word x. The authors of the paper use the BATS dataset, which includes four relationships:
Encyclopedic semantics, such as personal-professional relationships like Einstein-physicist.
Lexicographic semantics, such as the antonym of cheap-expensive.
Derivational morphology, such as oblige (verb, to compel) and obligation (noun, obligation).
Inflectional morphology, such as bird-birds (singular and plural of bird).
Each relationship contains 10 subcategories.
As we said before, the word analogy task is to predict the word y that satisfies a : b :: x : y, and the difference of related word embeddings can largely reflect the similarity relationship, for example, queen (later) - king (king) ≈ woman (female) - man (male) largely means queen : king :: woman : man. Therefore, the word analogy problem can be solved by optimizing cos(b - a + x, y) (cos means cosine similarity, and a, b, x, and y are word embeddings). This method is generally referred to as the 3CosAdd method.
The author of the paper added pair2vec to 3CosAdd to get α·cos(ra,b, rx,y) + (1-α)·cos(b - a + x, y). Where r represents pair2vec embedding, α is a linear interpolation coefficient, α=0 is equivalent to the original 3CosAdd method, α=1 is equivalent to pair2vec.
The figure below shows the result of inserting pair2vec in FastText, the yellow line represents the derived morphology, the brown line represents the dictionary semantics, the green line represents the inflectional morphology, and the blue line represents the encyclopedic semantics.
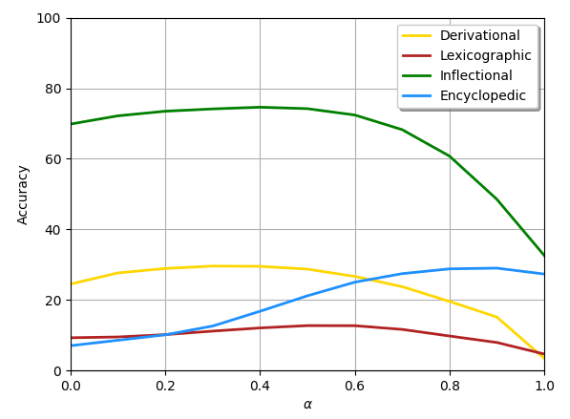
We can see that adding pair2vec to 3CosAdd achieves significant improvements across all four categories, with encyclopedic semantics (356%) and dictionary semantics (51%) being particularly prominent.
The table below shows the 10 subcategories with the most significant improvement, with α* being the optimal interpolation parameter.
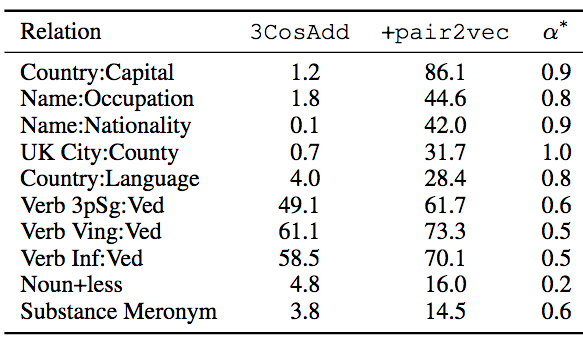
As we can see from the table above, the improvement is particularly significant on relations where the signal provided by FastText embeddings is very limited. The author of the paper also observed that there is a synergistic effect between pair2vec and FastText in some cases. For example, in the noun+less relationship, the original score of 3CosAdd is 4.8, and the score of pair2vec itself is 0, but after adding pair2vec to 3CosAdd, the score is 16.
fill the groove
To further explore how pair2vec encodes supplementary information, the authors try a slot filling task: given a Hearst-style context pattern c, word x, predict word y taken from the entire vocabulary. The ranking of candidate words y is based on the scoring function of the training target R(x,y)·C(c), using a fixed sample of relations, and manually defining context patterns and a small set of candidate words x.
The table below shows the top three y-words.
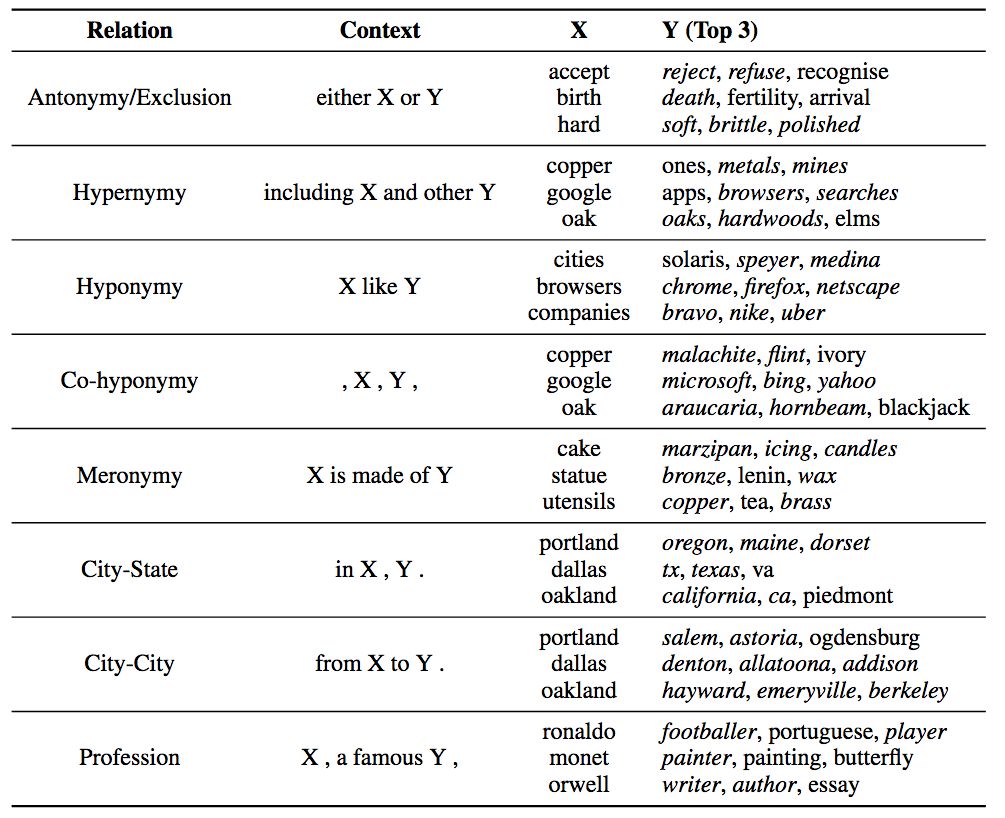
Italic indicates correct match
The above table shows that pair2vec can capture the trilateral relationship between word pairs and context, not just the bilateral relationship (word embedding) between a single word and context. This huge difference allows pair2vec to supplement word embeddings with additional information.
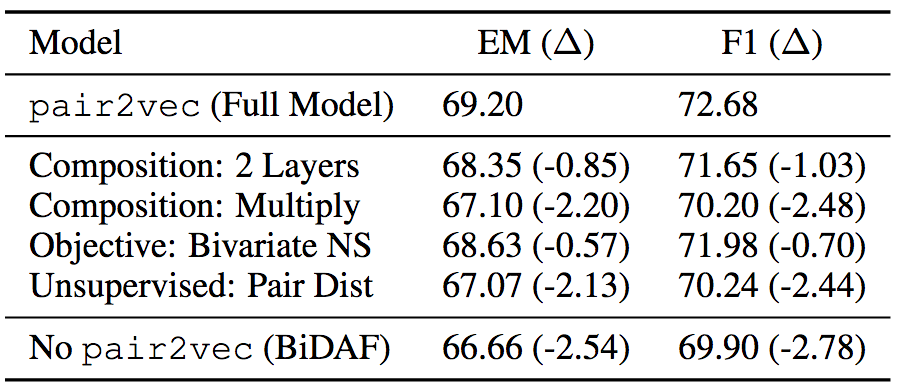
Ablation test
In order to verify the effectiveness of each component of pair2vec, the authors of the paper also performed an ablation test on the training set of SQuAD 2.0. Ablation tests show that enhanced sampling and the use of deeper compound functions are effective.
Epilogue
pair2vec is based on composite function representation, which effectively alleviates the sparsity problem of word pairs. The pair2vec pre-trained based on unsupervised learning can supplement information for word embeddings, thereby improving the performance of cross-sentence inference models.