Machine Learning: A Mammoth History of Artificial Intelligence Development
Lei Fengwang press: The author of this article DataCastle data castle, mainly introduces the history of machine learning from the generation, development, low tide and heyday.
AlphaGo's victory, driverless success, groundbreaking progress in pattern recognition, and the rapid development of artificial intelligence have once again stirred our nerves. As the core of artificial intelligence, machine learning is also attracting attention in the development of artificial intelligence.
Today, the application of machine learning has spread to various branches of artificial intelligence, such as expert systems, automatic reasoning, natural language understanding, pattern recognition, computer vision, intelligent robots and other fields.
But perhaps we have never thought of the origin of machine learning and even artificial intelligence. It is an exploration of philosophical issues such as human consciousness, self, and soul. In the process of development, it integrates the knowledge of disciplines such as statistics, neuroscience, information theory, cybernetics, and computational complexity theory.

In general, the development of machine learning is an important branch of the entire history of artificial intelligence. The story twists and turns, surprisingly amazed, quite soul-stirring.
Among the stories that are interspersed with countless cows, in the following introduction, you will see the appearance of the following god-level characters. We follow the progress of ML's timeline:

From the early 1950s to the mid 60s
Hebb started the first step of machine learning in 1949 based on neuropsychology learning mechanisms. It was later called the Hebb learning rule . The Hebb learning rule is an unsupervised learning rule. The result of this learning is to enable the network to extract the statistical characteristics of the training set so that the input information is divided into several classes according to their degree of similarity. This is very consistent with the process of human observation and understanding of the world. To a certain extent, human observation and understanding of the world are based on the statistical characteristics of things.
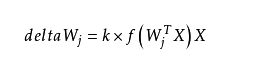
From the above formula, we can see that the amount of weight adjustment is proportional to the product of input and output. It is obvious that the frequently occurring modes will have a greater impact on the weight vector. In this case, the Hebb learning rule requires pre-determining the weight saturation value to prevent unconstrained growth of weights when the inputs and outputs are always consistent.
Hebb learning rules are consistent with the "conditional reflex" mechanism and have been confirmed by neuronal theory. For example, Pavlov's conditioned reflex experiment: every time before the dog feeds, it rings first. For a long time, the dog will connect the ring to the food. If you ring but do not give food later, the dog will drool.
In 1950, Alan Turing created the Turing test to determine if the computer was smart. The Turing test believes that if a machine can initiate a dialogue with humans (via telex devices) and cannot identify its machine identity, then the machine is called smart. This simplification makes Turing convincingly explain that "thinking machines" are possible.
On June 8, 2014, a computer (computer Eugene Gustman was a chat robot and a computer program) succeeded in convincing humans that it was a 13-year-old boy who became the first ever to pass the Turing test. computer. This is considered a milestone in the development of artificial intelligence.
In 1952, IBM scientist Arthur Samuel developed a checkers program . The program can provide better guidance for subsequent actions by observing the current position and learning an implicit model. Samuel found that with the increase in the running time of the game program, it can achieve better and better follow-up guidance.
Through this program, Samuel dismissed Providence's proposed machine that cannot transcend humans and write codes and learning patterns like humans. He created "machine learning" and defined it as "a research area that can provide computer capabilities without explicit programming."
In 1957, Rosenblatt proposed a second model based on a neural sensory science background, which is very similar to today's machine learning model. This was a very exciting discovery at the time and it was more applicable than Hebb's idea. Based on this model, Rosenblatt designed the first computer neural network, the perceptron , which simulates how the human brain operates.
Three years later, Verdello first used Delta learning rules for the sensor training steps. This method was later called the least squares method . The combination of the two creates a good linear classifier.
In 1967, the nearest neighbor algorithm (The nearest neighbor algorithm) occurs, whereby the computer can perform simple pattern recognition. The core idea of ​​the kNN algorithm is that if most of the k most adjacent samples in a feature space belong to a certain category, the sample also belongs to this category and has the characteristics of the samples in this category. This method determines the class to which the sample is to be classified based on the category of the nearest one or several samples in determining the classification decision.
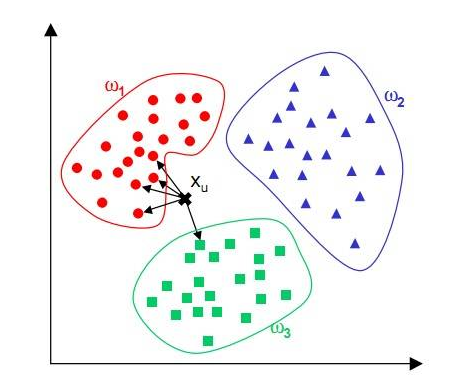
The advantages of kNN are that it is easy to understand and implement, it doesn't need to estimate parameters, it doesn't need training, and it is suitable for classifying rare events. It is especially suitable for multi-modal problems (objects have multiple category tags), and even better than SVM.
Han et al. (2002) attempted to use the greedy method to implement weighted adjusted k nearest neighbors (WAkNN) for document classification with adjustable weights; this was promoted by Li et al. in 2004 because of different classifications. There are differences in the number of documents themselves, so it is also necessary to select different numbers of nearest neighbors to participate in the classification according to the number of documents classified in the training set.
In 1969, Marvin Minsky pushed the sensory excitement to the highest point. He proposed the well-known XOR problem and perceptron data are linearly inseparable.
Minsky also combined artificial intelligence technology and robotics technology to develop the world's first robot Robot C capable of simulating human activities, making robotics technology a new level. Minsky's other big move was the creation of the famous Thinking Machines, Inc. to develop smart computers.
Since then, neural network research will be dormant until the 1980s. Although the idea of ​​a BP nerve was proposed by Linnainma in 1970 and referred to as the “automated differentiation reverse modeâ€, it did not attract enough attention.
| Calm down periods of stagnationFrom the mid-1960s to the late 1970s
From the mid-1960s to the end of the 1970s, the pace of machine learning was almost at a standstill. Although Winston (Winston) structure learning system and Hayes Roth (Hayes Roth), etc. has made great progress learning system based on inductive logic of this period, but only learning a single concept, but failed to put into practice . In addition, the neural network learning machine turns into a low ebb because of the failure of theoretical defects to achieve the desired results.
The research goal of this period is to simulate the concept learning process of humans , and use the logical structure or graph structure as the internal description of the machine. Machines can use symbols to describe concepts (acquisition of symbol concepts) and make assumptions about learning concepts.
In fact, the entire AI sector has encountered bottlenecks during this period. The limited memory and processing speed of the computer at the time was not sufficient to solve any practical AI problem. Asking the program to understand the world as a child, the researchers quickly discovered that the requirement was too high: no one could make such a huge database in 1970, and nobody knew how a program could learn such a wealth of information.
| Resurrection of HopeFrom the late 1970s to the mid 1980s
Since the late 1970s, people have expanded from learning a single concept to learning multiple concepts , exploring different learning strategies and various learning methods. During this period, machine learning returned to people's attention in a large amount of time and slowly recovered.
In 1980, the first International Workshop on Machine Learning was held at Carnegie Mellon University (CMU) in the United States, marking the rise of machine learning research around the world. After that, the machine learns to learn to enter the application.
After some setbacks, the Multilayer Perceptron (MLP) was specifically proposed by Weibos in the 1981 Neural Network Back Propagation (BP) algorithm. Of course, BP is still a key factor in today's neural network architecture. With these new ideas, the study of neural networks has accelerated.
1985-1986 neural network researchers (Rummelhardt, Hinton, Williams-He, Nelson) proposed the concept of combining MLP and BP training.
A very famous ML algorithm was proposed by Quinlan in 1986. We call it a decision tree algorithm , more precisely the ID3 algorithm. This is another spark of the mainstream machine learning. In addition, in contrast to the black box neural network model, the decision tree ID3 algorithm is also used as a software, and by using simple rules and clear references, more real-life use cases can be found.
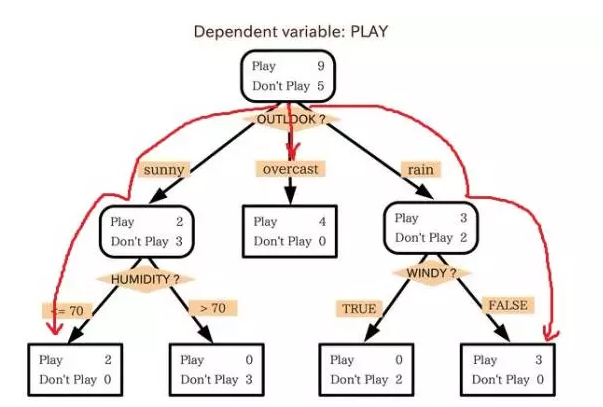
Weather Classification Decision for Playing Tennis in Machine Learning
The decision tree is a predictive model. It represents a mapping relationship between object attributes and object values. Each node in the tree represents an object, and each forked path represents a possible attribute value, and each leaf node corresponds to the object represented by the path from the root node to the leaf node. value. Decision trees have only a single output. If you want to have multiple outputs, you can build an independent decision tree to handle different outputs. Decision tree in data mining is a frequently used technology that can be used to analyze data and can also be used for prediction.
| The shaping period of modern machine learningFrom the beginning of the 20th century to the early 21st century
In 1990, Schapire first constructed a polynomial-level algorithm that gave a positive proof of the problem. This is the original Boosting algorithm. One year later, Freund proposed a more efficient Boosting algorithm. However, these two algorithms have common practical drawbacks, that is, they all require that the weak learning algorithm learn the correct lower limit in advance.
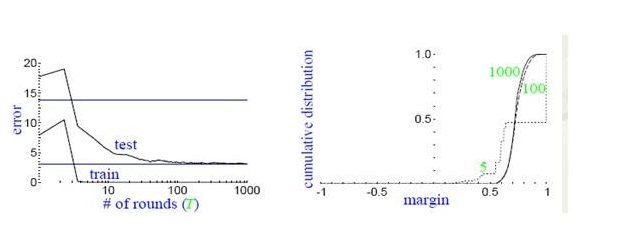
In 1995, Freund and Schapire improved the Boosting algorithm and proposed the AdaBoost (Adap tive Boosting) algorithm. The algorithm efficiency is almost the same as the Boosting algorithm proposed by Freund in 1991, but does not require any prior knowledge about the weak learner. It is easier to apply to practical problems.
The Boosting method is a method to improve the accuracy of weak classification algorithms by constructing a series of prediction functions and then combining them into a prediction function in a certain way. He is a framework algorithm, which mainly obtains sample subsets through the operation of sample sets, and then uses a weak classification algorithm to train a sample subset to generate a series of base classifiers.
In the same year, the field of machine learning one of the most important breakthrough, support vector (support vector machines, SVM), a wap and Nick Cortes put forward under the conditions of a large number of theoretical and empirical. Since then, the machine learning community has been divided into a neural network community and a support vector machine community.
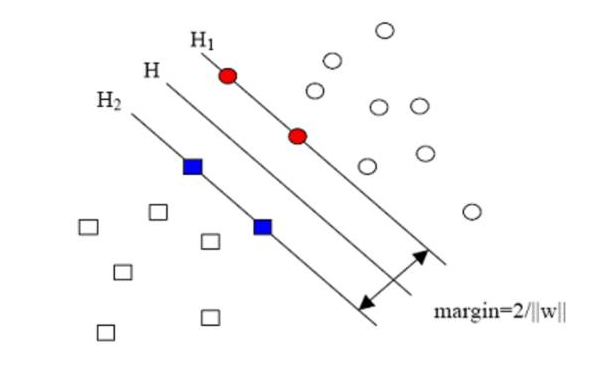
However, the competition between the two communities is not so easy. The neural network is lagging behind the SVM-nuclear version for nearly 2000s. Support vector machines (SVMs) have achieved good results in many tasks that could not be solved by previous neural network models. In addition, the support vector machine can use all prior knowledge to make convex optimization choices, resulting in accurate theoretical and nuclear models. As a result, it can give a big boost to different disciplines, resulting in very efficient theoretical and practical improvements.
Support vector machine, Boosting, maximum entropy method (such as logistic regression, LR) and so on. The structure of these models can basically be seen as a hidden layer node (such as SVM, Boosting), or no hidden layer nodes (such as LR). These models have achieved great success both in theoretical analysis and in their application.
Another integrated decision tree model was proposed by Dr. Breman in 2001. It consists of an instance of a random subset, and each node is selected from a series of random subsets. Because of this nature of it, known as Random Forest (RF), Random Forest also proved theoretically and empirically the resistance to overfitting.
Even the AdaBoost algorithm shows weaknesses in data overfitting and outlier instances, and Random Forest is a more robust model for these warnings. Random forests have shown success in many different missions, such as DataCastle, Kaggle and others. 
| The flourishing period of development
21st century to the present
Machine learning development is divided into two parts, the shallow learning (Shallow Learning) and deep learning (Deep Learning). The invention of shallow learning origin The back-propagation of artificial neural networks in the 1920s made statistically based machine learning algorithms popular, even though artificial neural network algorithms at this time are also called multilayer perceptrons ( Multiple layer Perception), but due to the difficulty of multi-layer network training, there is usually a shallow model with only one hidden layer.
In 2006, Hinton, a leader in neural network research, proposed the neural network Deep Learning algorithm, which greatly improved the capabilities of neural networks and sent challenges to support vector machines. In 2006, Hinton, a master of machine learning, and Salakhutdinov, his student, published an article in the leading academic journal Scince, opening up a wave of deep learning in the academic and industrial world.
This article has two main messages:
1) Many hidden layer artificial neural networks have excellent feature learning capabilities, and the learned features have more essential characterization of the data, which is conducive to visualization or classification;
2) The difficulty of deep neural network training can be effectively overcome by layer-wise pre-training. In this article, layer-by-layer initialization is achieved through unsupervised learning.
Hinton student Yann LeCun 's LeNets deep learning network can be widely used in ATMs and banks around the world. At the same time, Yann LeCun and Wu Enda think that convolutional neural networks allow artificial neural networks to be trained quickly, because they use very little memory and do not have to store filters separately at every position on the image, so they are very suitable for building scalable networks. The deep network, convolutional neural network is therefore very suitable for identifying models.
In 2015, in commemoration of the 60th anniversary of the concept of artificial intelligence, LeCun, Bengio and Hinton launched a joint review of deep learning.
Deep learning allows computational models with multiple processing layers to learn representations of data with multiple levels of abstraction. These methods have brought significant improvements in many areas, including state-of-the-art speech recognition, visual object recognition, object detection, and many other areas such as drug discovery and genomics. Deep learning can find complex structures in big data. It uses BP algorithm to complete this discovery process. The BP algorithm can instruct the machine how to obtain errors from the previous layer and change the internal parameters of the layer. These internal parameters can be used to calculate the representation. Deep convolutional networks have made breakthroughs in processing images, video, speech, and audio, and recursive networks have shown a shiny side in processing sequence data such as text and speech.
Currently, the most popular methods in statistical learning include deep learning and SVM (support vector machine), which are representative methods of statistical learning. It can be considered that both the neural network and the support vector machine originate from the perceptron.
Neural networks and support vector machines have always been in a "competitive" relationship. The expansion theorem of SVM application kernel function does not need to know the explicit expression of nonlinear mapping; because it is a linear learning machine built in the high-dimensional feature space, compared with the linear model, it not only increases the computational complexity, but also To some extent, avoiding "dimensional disasters." The previous neural network algorithm is relatively easy to train, a large number of empirical parameters need to be set; the training speed is slower, and the effect is not better than other methods when the level is relatively small (less than or equal to 3).
Neural network models seem to be able to achieve more difficult tasks, such as target recognition, speech recognition, natural language processing and so on. However, it should be noted that this absolutely does not mean the end of other machine learning methods. Although the success stories of deep learning have grown rapidly, the training cost for these models is quite high, and adjusting external parameters is also very troublesome. At the same time, the simplicity of SVM makes it still the most widely used machine learning method.

Artificial intelligence machine learning is a young discipline that was born in the middle of the 20th century. It has had a major impact on human production and lifestyle, and it has also triggered fierce philosophical debates. But in general, the development of machine learning is not much different from the development of other common things. It can also be viewed from the perspective of the development of philosophy.
The development of machine learning has not been easy. It has also undergone a process of spiraling up. Achievements and ups and downs coexist. The achievements of a large number of research scholars have brought unprecedented prosperity to today's artificial intelligence, and it is a process of quantitative change to qualitative change. It is also the common result of internal and external factors.
Looking back, we will be convinced by this magnificent history.
Lei Feng Network (Search "Lei Feng Network" public concern) Note: This article is authorized by DataCastle Data Castle authorized Lei Feng network, for reprint please contact the original author, and indicate the author and the source can not be deleted.
Pcb Pluggable Terminal Block Connector ,Pluggable Terminal Block,Contact Pluggable Terminal Blocks ,Pluggable Screw Terminal
Cixi Xinke Electronic Technology Co., Ltd. , https://www.cxxinke.com